Un catalogue THREDDS décrit les jeux de données d'un serveur et comment ils peuvent être consultés. Un catalogue est un document XML qui suit le schéma du catalogue THREDDS.
Les catalogues THREDDS collectent, organisent et décrivent des jeux de données accessibles via le TDS. Ils fournissent une structure hiérarchique pour l'organisation des jeux de données, ainsi qu'une méthode d'accès (URL) liée à un service et un nom humainement compréhensible pour chaque jeu de données. Des descriptions supplémentaires pour chaque jeu de données peuvent également être ajoutées.
Arborescence de l'appication TDS
 Toutes les informations de configuration TDS sont stockées dans le répertoire de
Toutes les informations de configuration TDS sont stockées dans le répertoire de content de Tomcat. L'emplacement du répertoire est contrôlé par l'attribut Java tds.content.root.path. L'emplacement par défaut est ${tomcat_home}/content/, toutefois, il est fortement recommandé de définir explicitement cette valeur dans le script de démarrage Tomcat ou dans le fichier setenv.sh.
Chemins dans l'arborescence Tomcat
Le répertoire content est créé et rempli avec les fichiers par défaut la première fois que le TDS est déployé. Il est persistant même lorsqu'une installation TDS est mise à niveau ou redéployée. Toutes les configurations, modifications et ajouts doivent être faits dans ce répertoire. Ne pas placer de fichiers contenant des mots de passe ou quoi que ce soit d'autre présentant des problèmes de sécurité dans ce répertoire. Généralement, seuls les catalogues et les fichiers de configuration sont modifiés.
Les principaux fichiers qui vont nous intéresser dans un premier temps sont les suivant :
/opt/tomcat/content/thredds/catalog.xml- fichier principal de configuration des catalogues TDSthreddsConfig.xml- fichier de configuration de l'application THREDDS (description détaillée ici)logs/catalogInit.log- fichier contenant les logs produits par la lecture de la configuration des catalogues lors de l'initialisation de l'application THREDDSthreddsServlet.log- fichier contenant les logs relatifs aux requêtes vers les serveur TDS incluant les messages d'erreur
cache/- divers répertoire de cache :- agg/
- cdm/
- collection/
- ehcache/
- ncss/
- wcs/
Le catalogue racine de TDS
Le principal catalogue de configuration du serveur THREDDS est le fichier <tds.content.root.path>/thredds/catalog.xml. A l'installation de TDS, un fichier catalog.xml est créé par défaut :
$ cd /opt/tomcat/content/thredds/
$ less catalog.xml
<?xml version="1.0" encoding="UTF-8"?>
<catalog name="THREDDS Server Default Catalog : You must change this to fit your server!"
xmlns="http://www.unidata.ucar.edu/namespaces/thredds/InvCatalog/v1.0"
xmlns:xlink="http://www.w3.org/1999/xlink"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.unidata.ucar.edu/namespaces/thredds/InvCatalog/v1.0
http://www.unidata.ucar.edu/schemas/thredds/InvCatalog.1.0.6.xsd">
<service name="all" base="" serviceType="compound">
<service name="odap" serviceType="OpenDAP" base="/thredds/dodsC/" />
<service name="dap4" serviceType="DAP4" base="/thredds/dap4/" />
<service name="http" serviceType="HTTPServer" base="/thredds/fileServer/" />
<!--service name="wcs" serviceType="WCS" base="/thredds/wcs/" /-->
<!--service name="wms" serviceType="WMS" base="/thredds/wms/" /-->
<!--service name="ncss" serviceType="NetcdfSubset" base="/thredds/ncss/" /-->
</service>
<service name="dap" base="" serviceType="compound">
<service name="odap" serviceType="OpenDAP" base="/thredds/dodsC/" />
<service name="dap4" serviceType="DAP4" base="/thredds/dap4/" />
</service>
<datasetRoot path="test" location="content/testdata/" />
<dataset name="Test Single Dataset" ID="testDataset"
serviceName="dap" urlPath="test/testData.nc" dataType="Grid"/>
<dataset name="Test Single Dataset 2" ID="testDataset2"
serviceName="odap" urlPath="test/testData2.grib2" dataType="Grid"/>
<datasetScan name="Test all files in a directory" ID="testDatasetScan"
path="testAll" location="content/testdata">
<metadata inherited="true">
<serviceName>all</serviceName>
<dataType>Grid</dataType>
</metadata>
<filter>
<include wildcard="*eta_211.nc"/>
<include wildcard="testgrid*.nc"/>
</filter>
</datasetScan>
<catalogRef xlink:title="Test Enhanced Catalog" xlink:href="enhancedCatalog.xml" name=""/>
</catalog>
Lorsque le TDS démarre, ce catalogue de configuration est lu, comme tous les catalogues de l'arborescence du catalogue définis par les éléments <catalogRef>. L'arborescence de catalogue qui en résulte est utilisée comme les catalogues racines servis par le TDS. Dans le cas de notre catalogue de test, l'arborescence ressemble à :
catalog.xml
|
|-- enhancedCatalog.xml
On peut ainsi imbriquer autant de catalogue que souhaité.
Configuration du Catalogue TDS
Cette section décrit les paramètres du catalogue qui configurent la vue client du catalogue et l'accès aux données.
Déclaration du schéma XML
1. <?xml version="1.0" encoding="UTF-8"?>
2. <catalog name="THREDDS Server Default Catalog : You must change this to fit your server!"
xmlns="http://www.unidata.ucar.edu/namespaces/thredds/InvCatalog/v1.0"
xmlns:xlink="http://www.w3.org/1999/xlink"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.unidata.ucar.edu/namespaces/thredds/InvCatalog/v1.0
http://www.unidata.ucar.edu/schemas/thredds/InvCatalog.1.0.6.xsd">
...
3. </catalog>
avec l'explication ligne par ligne :
1 - La première ligne indique qu'il s'agit d'un document XML.
2 - C'est l'élément racine du XML, l'élément du catalogue. Il doit déclarer l'espace de noms (namespace) du catalogue THREDDS avec l'attribut xmlns exactement comme indiqué.
3 - Ceci ferme l'élément de catalogue.
Déclaration des services de données
Les jeux de données servis par un serveur THREDDS peuvent être accessibles via plusieurs protocoles d'accès aux données. Ces protocoles sont définis par la balise <service> du catalogue (Liste des services TDS)
1. <service name="odap" serviceType="OpenDAP" base="/thredds/dodsC/" />
2. <service name="dap4" serviceType="DAP4" base="/thredds/dap4/" />
3. <service name="http" serviceType="HTTPServer" base="/thredds/fileServer/" />
4. <!--service name="wcs" serviceType="WCS" base="/thredds/wcs/" /-->
5. <!--service name="wms" serviceType="WMS" base="/thredds/wms/" /-->
6. <!--service name="ncss" serviceType="NetcdfSubset" base="/thredds/ncss/" /-->
1 - déclare un service nommé odap qui servira les données via le protocole OpenDAP (DAP v2).
2 - déclare un service nommé dap4 qui servira les données via le protocole DAP v4.
3 - déclare un service nommé http qui servira les données via le protocole HTTP (téléchargement direct du fichier de données).
4 - (commentée) déclare une service wcs qui servira les données via le protocole OGC Web Coverage Service.
5 - (commentée) déclare une service wms qui servira les données via le protocole OGC Web Mapping Service.
6 - (commentée) déclare une service ncss qui servira les données via le protocole NetCDF Subset Service.
Les services de données peuvent être regroupés dans un service de type compound. Par exemple :
<service name="all" base="" serviceType="compound">
<service name="odap" serviceType="OpenDAP" base="/thredds/dodsC/" />
<service name="dap4" serviceType="DAP4" base="/thredds/dap4/" />
<service name="http" serviceType="HTTPServer" base="/thredds/fileServer/" />
</service>
définit un service all qui regroupe les services odap, dap4 et http.
Note
Le nom de service défini dans l'attribut name de la balise <service> doit être unique au sein d'un même catalogue ou au sein d'un même compound service.
Attention
Conditions requises en fonction des services :
- Le service "HTTPServer" peut servir tout type de fichier.
- Le service "OPeNDAP" peut servir tout type de fichier pouvant être reconnu par la librairie NetCDF-Java.
- Le service "WCS" ne peut servir que les fichiers reconnus par la librairie netCDF-Java comme données "gridded".
- Le service "WMS" ne peut servir que les fichiers reconnus par la librairie netCDF-Java comme données "gridded".
- Le service "NetcdfSubset" ne peut servir que les fichiers reconnus par la librairie netCDF-Java comme données "gridded".
Construction de l'URL d'accès au jeu de données
En suivant l'exemple ci-dessus, voici comment le serveur THREDDS construit l'URL d'accès au jeu de données:
- Chaque URL dépend du service d'accès au jeu de données. Dans l'exemple précédent, pour le service OpenDAP :
<service name="odap" serviceType="OpenDAP" base="/thredds/dodsC/" />
<dataset name="Test Single Dataset" ID="testDataset" serviceName="dap" urlPath="test/testData.nc" dataType="Grid"/>
- Le serveur concatène le chemin d'accès de base au service (
base="/thredds/dodsC/") avec le server root pour construire l'URL de base du service :
serverRoot = http://hostname:port
serviceBasePath = /thredds/dodsC/
serviceBaseUrl = serverRoot + serviceBasePath = http://hostname:port/thredds/dodsC/
- L'URL est ensuite complétée avec le chemin d'accès au jeu de données. Dans l'exemple précédent :
<dataset name="Test Single Dataset" ID="testDataset" serviceName="dap" urlPath="test/testData.nc" dataType="Grid"/>
- Le chemin complet résultant :
serviceBaseUrl = http://hostname:port/thredds/dodsC/
datasetUrlPath = test/testData.nc
datasetAccessUrl = serviceBaseUrl + datasetUrlPath = http://hostname:port/thredds/dodsC/test/testData.nc
- En résumé, l'URL est constituée de trois parties :
http://hostname:port/thredds/dodsC/test/testData.nc
<------------------><------------><--------------->
server service dataset
Attention
Les base paths des services d'accès aux données sont prédéfinis par le serveur TDS. Ainsi, les base paths de ces services doivent suivre les valeurs indiquées ci-dessous en fonction du service:
- OPeNDAP
<service name="odap" serviceType="OPeNDAP" base="/thredds/dodsC/" /> - NetCDF Subset Service
<service name="ncss" serviceType="NetcdfSubset" base="/thredds/ncss/" /> - WCS
<service name="wcs" serviceType="WCS" base="/thredds/wcs/" /> - WMS
<service name="wms" serviceType="WMS" base="/thredds/wms/" /> - HTTP Bulk File Service
<service name="fileServer" serviceType="HTTPServer" base="/thredds/fileServer/" />
Déclaration d'un jeu de données
Le but principal d'un serveur THREDDS est de décrire et donner accès à des jeux de données. Deux éléments du catalogue THREDDS vont permettre de décrire le mapping entre les fichiers de données et la manière de les présenter via le serveur TDS :
1 - Les éléments datasetRoot et dataset
<datasetRoot path="mes/data" location="/mon/repertoire/de/donnees" />
<dataset name="Mes Donnees de Test" collectionType="TimeSeries" harvest="true">
<dataset name="Test Single Dataset" ID="testDataset" serviceName="dap" urlPath="mes/data/testData.nc" dataType="Grid"/>
<dataset name="Test Single Dataset 2" ID="testDataset2" serviceName="odap" urlPath="mes/data/testData2.nc">
<dataType>Grid</dataType>
<dataFormatType>NetCDF</dataFormatType>
</dataset>
</dataset>
Chaque élément datasetRoot définit un mappage unique entre un chemin de base d'URL et un répertoire. Dans l'exemple ci-dessus, l'élément /mes/data/ de l'URL sera mappé sur le répertoire /mon/repertoire/de/donnees. L'utilisateur tomcat doit avoir les droits de lecture sur ce répertoire et les fichiers de données servis par TDS.
Le jeu de données est déclaré par la balise <dataset>, qui comprend les attributs suivant :
name: Nom Human-Readable du datasetID: Identifiant unique(dans ce catalogue) du datasetserviceName: Nom du service d'accès au dataseturlPath: URL d'accès au datasetdataType: Cet élément permet de décrire le type de données pour en faciliter la représentation par des applications clientes (ex. : Image, Grid, Point, etc...)collectionType: décrit le lien entre des jeux de données imbriqués (ex. :collectionType="TimeSeries")dataFormatType: indique le format des donnéesharvest="true": indique aux applications clientes le jeu de données à moissonner.
Comme dans l'exemple ci-dessus, un dataset peut contenir d'autres datasets. Pour partager les attributs ou métadonnées entre les jeux de données, on utilise la balise <metadata> :
<dataset name="Mes Donnees de Test" collectionType="TimeSeries">
<metadata inherited="true">
<serviceName>odap</serviceName>
<dataFormatType>NetCDF</dataFormatType>
<dataType>Grid</dataType>
</metadata>
<dataset name="Test Single Dataset" ID="testDataset" urlPath="mes/data/testData.nc"/>
<dataset name="Test Single Dataset 2" ID="testDataset2" urlPath="mes/data/testData2.nc"/>
</dataset>
La liste exhaustive des attributs d'un dataset est disponible ici.
2 - L'élément datasetScan
<datasetScan name="Test all files in a directory" ID="testDatasetScan"
path="testAll" location="/mon/repertoire/de/donnees/testdata">
<metadata inherited="true">
<serviceName>all</serviceName>
<dataType>Grid</dataType>
</metadata>
<filter>
<include wildcard="*eta_211.nc"/>
<include wildcard="testgrid*.nc"/>
</filter>
</datasetScan>
Chaque élément datasetScan définit également un mappage unique entre un chemin de base d'URL et un répertoire. Contrairement à l'élément datasetRoot qui fonctionne avec les balises <dataset> pour définir les jeux de données servis, l'élément datasetScan servira automatiquement tout ou partie des jeux de données présents dans le répertoire mappé.
La balise <filter> permet de préciser les fichiers à inclure ou exclure dans l'arborescence scannée.
L'ensemble des règles de filtrage disponibles pour l'élément datasetScan est décrit sur cette page.
TP : Créer un catalogue Thredds
Le but du TP est de créer un catalogue THREDDS en intégrant progressivement les différentes fonctionnalités listées précédemment.
On suivra les résultats des modifications effecuées dans le fichier de catalogue THREDDS directement sur le site du TDS à l'adresse http://127.0.0.1:8080/thredds/
Note
Les messages d'informations et d'erreur liés à l'initialisation des catalogues sont visibles dans le fichier /opt/tomcat/content/thredds/logs/catalogInit.log
Déclaration d'un nouveau catalogue THREDDS
Plusieurs fichiers de données sont disponibles pour ce TP dans le répertoire /anfsist/data. Pour cette première étape, on utilisera les fichiers de profils de vents mesurés à l'observatoire du SIRTA à Palaiseau. Deux séries de fichiers sont disponibles :
- un fichier NetCDF dans lequel ont été concaténées les données du 01/03/2017 au 10/03/2017
- un répertoire contenant les mêmes données du 01/03/2017 au 10/03/2017, mais stockées dans des fichiers journaliers.
Dans la suite du TP, en utilisant les deux modes de déclaration d'un jeu de données dans TDS, datasetRoot et datasetScan, on créera un catalogue Sirta Dataset contenant les deux séries de données.
Note
Pour simplifier l'édition des fichiers de configuration lors de ce TP, changer le owner de ces fichiers vers l'utilisateur sist (les fichiers doivent être lisibles par tomcat, mais le serveur n'écrit pas dans ces fichiers).
cd /opt/tomcat/content/thredds
sudo chown sist *.xml
sudo chown sist .
Déclarer un nouveau fichier de catalogue dans le catalogue racine
 Editer le fichier
Editer le fichier catalog.xmlde THREDDS pour référencer un nouveau fichier de déclaration de catalogue grâce à la balisecatalogRef
$ cd /opt/tomcat/content/thredds/
# Utiliser l'éditeur de votre choix (gedit, code, vi,...)
$ vi catalog.xml
- Ajouter la ligne de déclaration de catalogue :
<catalogRef xlink:href="sirta-catalog.xml" xlink:title="Sirta Dataset" ID="SirtaSet" name=""/>
Référencer un fichier de données via les balises datasetRoot et dataset
 Editer le nouveau fichier de catalogue pour référencer le fichier de profils de vents de l'observatoire atmosphérique du SIRTA : `/anfsist/data/sirta/profilvent_1a_Lmat10mLz1PventR5sN5n_v01_20170301-20170310.nc`
$ vi sirta-catalog.xml
<?xml version="1.0" encoding="UTF-8"?>
<catalog xmlns="http://www.unidata.ucar.edu/namespaces/thredds/InvCatalog/v1.0" xmlns:xlink="http://www.w3.org/1999/xlink"
name="SIRTA Data Catalog" >
<!-- On déclare le mapping entre l'URL d'accès aux données et leur répertoire sur le serveur -->
<datasetRoot path="sirta" location="/anfsist/data/sirta"/>
<!-- On déclare le jeu de données -->
<dataset name="Sirta Wind Profiles" ID="SirtaWP" dataType="Grid"
urlPath="sirta/profilvent_1a_Lmat10mLz1PventR5sN5n_v01_20170301-20170310.nc"/>
</catalog>
- Redémarrer le serveur Tomcat pour ré-initialiser le catalogue Thredds.
# Arrêt du serveur Tomcat
$ sudo -u tomcat /opt/tomcat/bin/shutdown.sh
# Vérifier que le Serveur est arrêté
$ ps -eaf |grep java
# Démarrage du serveur Tomcat
$ sudo -u tomcat /opt/tomcat/bin/startup.sh
-
Un nouveau catalogue de données, intitulé Sirta Dataset, apparaît sur le catalogue THREDDS http://127.0.0.1:8080/thredds/
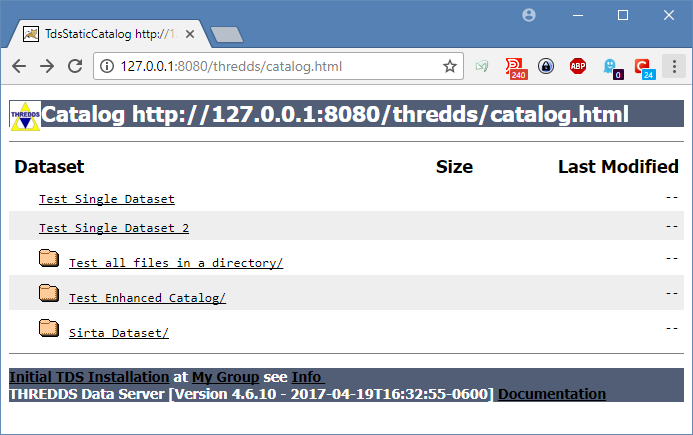
-
Ce nouveau catalogue contient actuellement un seul jeu de données Sirta Wind Profiles
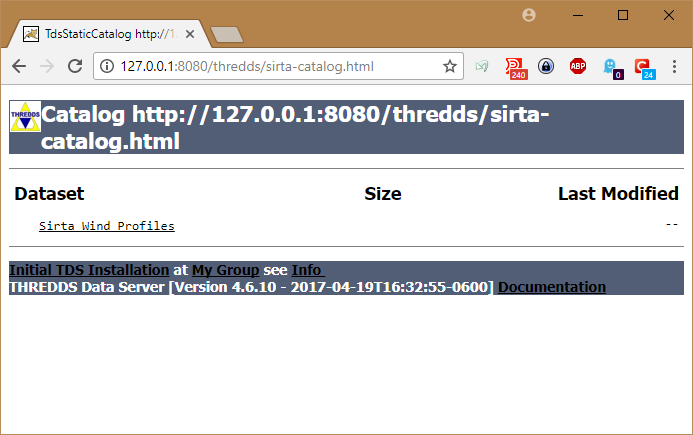
-
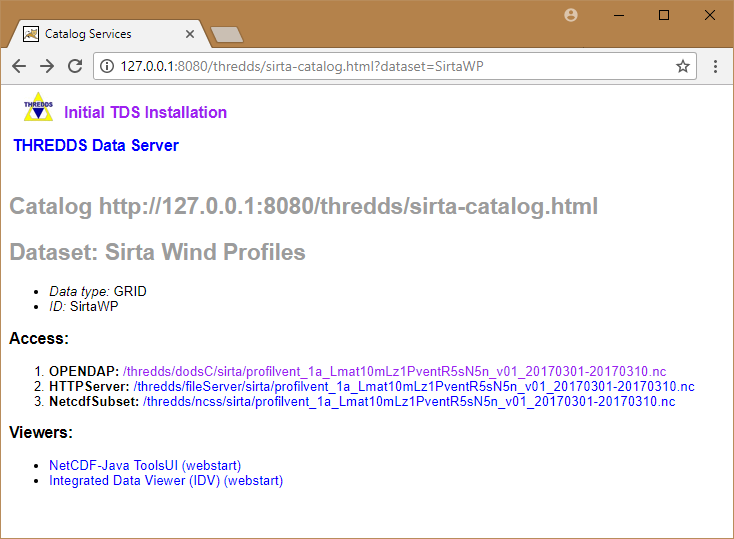
La page du jeu de données Sirta Wind Profiles ne permet pas, pour l'instant, d'accéder aux données, puisqu'aucun service THREDDS n'a été précisé pour cet accès.
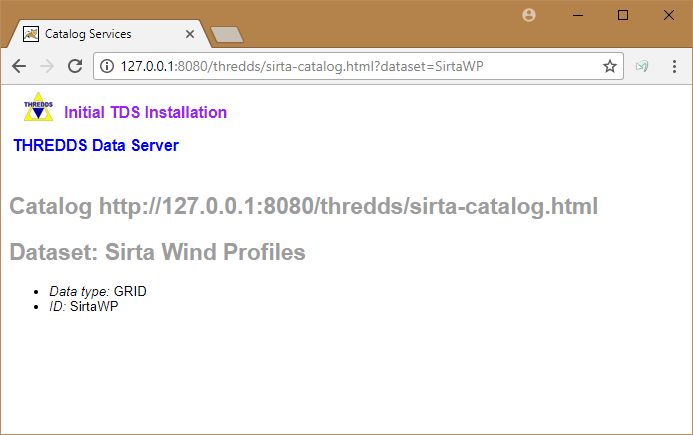
 Editer le fichier `sirta-catalog.xml` pour ajouter les services **odap**, **http** et **ncss** d'accès aux données
<?xml version="1.0" encoding="UTF-8"?>
<catalog xmlns="http://www.unidata.ucar.edu/namespaces/thredds/InvCatalog/v1.0" xmlns:xlink="http://www.w3.org/1999/xlink"
name="SIRTA Data Catalog" >
<service name="all" base="" serviceType="compound">
<service name="odap" serviceType="OpenDAP" base="/thredds/dodsC/" />
<service name="http" serviceType="HTTPServer" base="/thredds/fileServer/" />
<service name="ncss" serviceType="NetcdfSubset" base="/thredds/ncss/" />
</service>
<!-- On déclare le mapping entre l'URL d'accès aux données et leur répertoire sur le serveur -->
<datasetRoot path="sirta" location="/anfsist/data/sirta"/>
<!-- On déclare le jeu de données -->
<dataset name="Sirta Wind Profiles" ID="SirtaWP" serviceName="all" dataType="Grid"
urlPath="sirta/profilvent_1a_Lmat10mLz1PventR5sN5n_v01_20170301-20170310.nc"/>
</catalog>
- L'ajout des services dans le fichier XML permet d'activer également la section viewers sur la page web du jeu de données :
- Le service http active le client NetCDF-Java ToolsUI (webstart)
- Le service odap active le client Integrated Data Viewer (IDV) (webstart)
Référencer un fichier de données via la balise datasetScan
 Editer le nouveau fichier de catalogue pour référencer les fichiers de profils de vents de l'observatoire atmosphérique du SIRTA du répertoire : `/anfsist/data/sirta/201703/`
<?xml version="1.0" encoding="UTF-8"?>
<catalog xmlns="http://www.unidata.ucar.edu/namespaces/thredds/InvCatalog/v1.0" xmlns:xlink="http://www.w3.org/1999/xlink"
name="SIRTA Data Catalog" >
<service name="all" base="" serviceType="compound">
<service name="odap" serviceType="OpenDAP" base="/thredds/dodsC/" />
<service name="http" serviceType="HTTPServer" base="/thredds/fileServer/" />
<service name="ncss" serviceType="NetcdfSubset" base="/thredds/ncss/" />
</service>
<!-- On déclare le mapping entre l'URL d'accès aux données et leur répertoire sur le serveur -->
<datasetRoot path="sirta" location="/anfsist/data/sirta"/>
<!-- On déclare le jeu de données -->
<dataset name="Sirta Wind Profiles" ID="SirtaWP" serviceName="all" dataType="Grid"
urlPath="sirta/profilvent_1a_Lmat10mLz1PventR5sN5n_v01_20170301-20170310.nc"/>
<!-- Jeu de données multi-fichiers -->
<!-- Attention le Path ne doit pas déjà exister dans un autre datasetRoot ou datasetScan -->
<datasetScan name="Sirta Wind Profiles MultiFiles" ID="SirtaWPMultiFile"
path="sirtadir" location="/anfsist/data/sirta/201703/">
<metadata inherited="true">
<serviceName>all</serviceName>
<dataType>Grid</dataType>
</metadata>
<filter>
<include wildcard="*.nc"/>
</filter>
</datasetScan>
</catalog>
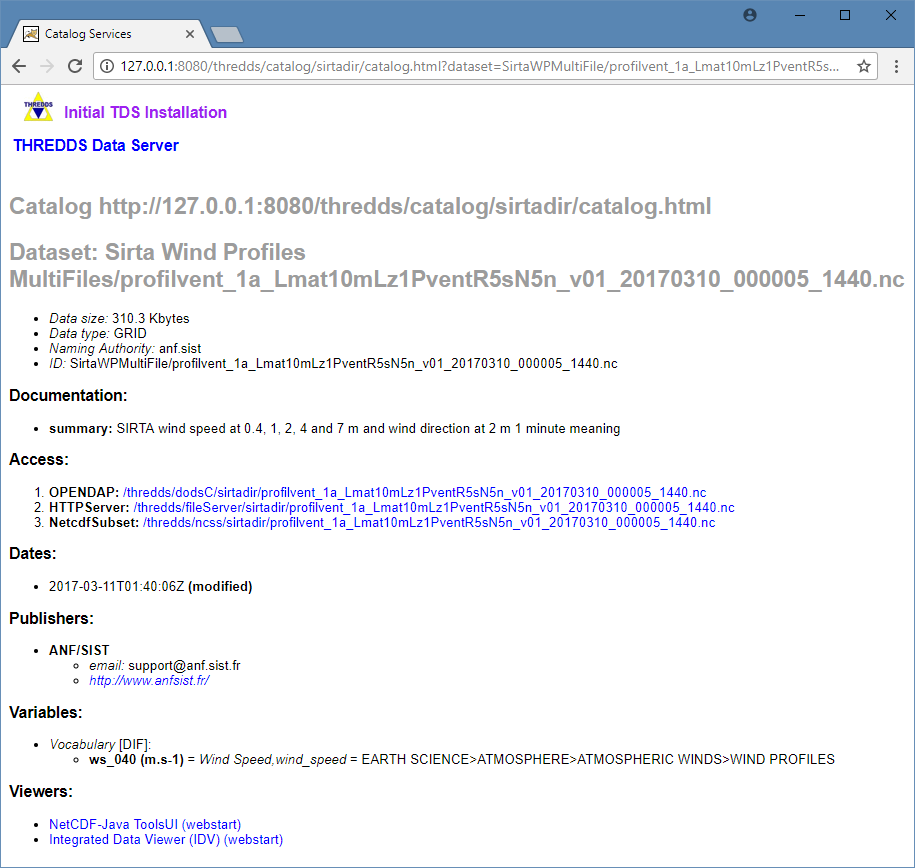
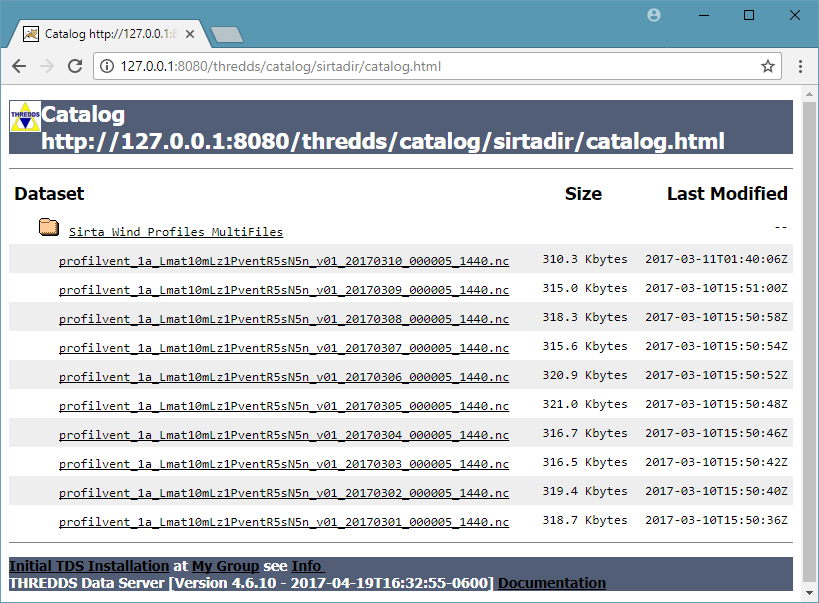
Le catalogue SIRTA présente un jeu de données Sirta Wind Profiles MultiFiles et l'ensemble des fichiers NetCDF du jeu de données. Pour chaque fichier, on retrouve les informations du dataset et les différents accès liés aux services TDS.
Ajouter des metadonnées
TDS permet d'ajouter des informations ou métadonnées pour décrire les jeux de données servis. La liste complète des attributs disponibles est accessible ici. Le tableau suivant donne par exemple la liste des attributs requis par la norme DIF.
- Champs requis
| Dataset Field | DIF Field | Notes |
|---|---|---|
| authority + ID | Entry_ID | |
| name | Entry_Title | |
| variables, vocabulary="DIF" | Parameters | encode as "Category > Topic > Term > Variable > Detailed Variable" |
| publisher | Data_Center | what about Originating_Center? |
| abstract | Summary | documentation, role="summary" or "abstract" better ?? |
- Champs optionnels
| Dataset Field | DIF Field | Notes |
|---|---|---|
| keyword | Keywords | uses all keywords, not just vocabulary="DIF" |
| timeCoverage | Temporal_Coverage | DIF cant handle reletive dates |
| geospatialCoverage | Spatial_Coverage | |
| rights | Use_Constraints | |
| Related_URL | refers to dynamic page generated by THREDDS server | |
| DIF_Creation_Date | generated automatically |
- Autres champs possibles
| Dataset Field | DIF Field | Notes |
|---|---|---|
| size | Distribution_Size | |
| dataFormat | Distribution_Format | multiple possible |
| service | Distribution_Media | multiple possible |
| contributor | Personell | role= "Investigator", "Technical Contact", "DIF Author" only |
| Source_Name | Platform valids | |
| project | Project | Project valids |
| Sensor_Name | Instrument valids |
 En s'inspirant de la déclaration des métadonnés dans le fichier `/opt/tomcat/content/thredds/enhancedCatalog.xml`, ajouter les métadonnées suivantes au jeu de données SIRTA référencé précédemment avec `datasetScan` : * **variable** *(voir lignes 56-57 du fichier enhancedCatalog.xml)* : * **vocabulaire** : DIF * **paramètre** : EARTH SCIENCE>ATMOSPHERE>ATMOSPHERIC WINDS>WIND PROFILES * **authority** *(voir ligne 14 du fichier enhancedCatalog.xml)* : Votre datacentre (autorité délivrant l'ID du dataset) * **publisher** *(voir lignes 23-26 du fichier enhancedCatalog.xml)* : * **nom** (vocabulaire : DIF) : Votre datacenter * **contact** : * **URL** : Page Web de votre datacenter * **e-mail** : adresse de contact de votre datacenter * **documentation, type summary** *(voir lignes 37 du fichier enhancedCatalog.xml)* : SIRTA wind speed at 0.4, 1, 2, 4 and 7 m and wind direction at 2 m 1 minute meaning
<?xml version="1.0" encoding="UTF-8"?>
<catalog xmlns="http://www.unidata.ucar.edu/namespaces/thredds/InvCatalog/v1.0" xmlns:xlink="http://www.w3.org/1999/xlink"
name="SIRTA Data Catalog" >
<service name="all" base="" serviceType="compound">
<service name="odap" serviceType="OpenDAP" base="/thredds/dodsC/" />
<service name="http" serviceType="HTTPServer" base="/thredds/fileServer/" />
<service name="ncss" serviceType="NetcdfSubset" base="/thredds/ncss/" />
</service>
<!-- On déclare le mapping entre l'URL d'accès aux données et leur répertoire sur le serveur -->
<datasetRoot path="sirta" location="/anfsist/data/sirta"/>
<!-- On déclare le jeu de données -->
<dataset name="Sirta Wind Profiles" ID="SirtaWP" serviceName="all" dataType="Grid"
urlPath="sirta/profilvent_1a_Lmat10mLz1PventR5sN5n_v01_20170301-20170310.nc"/>
<!-- Jeu de données multi-fichiers -->
<!-- Attention le Path ne doit pas déjà exister dans un autre datasetRoot ou datasetScan -->
<datasetScan name="Sirta Wind Profiles MultiFiles" ID="SirtaWPMultiFile"
path="sirtadir" location="/anfsist/data/sirta/201703/">
<metadata inherited="true">
<serviceName>all</serviceName>
<dataType>Grid</dataType>
<variables vocabulary="DIF">
<variable name="ws_040" vocabulary_name="EARTH SCIENCE>ATMOSPHERE>ATMOSPHERIC WINDS>WIND PROFILES" units="m.s-1">Wind Speed,wind_speed</variable>
</variables>
<authority>anf.sist</authority>
<publisher>
<name vocabulary="DIF">ANF/SIST</name>
<contact url="http://www.anfsist.fr/" email="support@anf.sist.fr" />
</publisher>
<documentation type="summary">SIRTA wind speed at 0.4, 1, 2, 4 and 7 m and wind direction at 2 m 1 minute meaning</documentation>
</metadata>
<filter>
<include wildcard="*.nc"/>
</filter>
</datasetScan>
</catalog>
Sur la capture d'écran suivante, on retouve les métadonnées ajoutées au jeu de données SIRTA.